

レポーティングは、ほとんどのユーザーが最も多くの時間を費やす部分であり、データを理解し、最適化の方法を見出そうとしています。
以下では、レポーティングページとその使用方法について説明します。また、私たちのクイックスタッツとキャンペーン分析の記事もご覧ください。これらのレポートはしばしば速く、必要な基本データを得ることができます。
また、レポーティングヘルプセクションで他の多くの記事もチェックできます。
レポーティングの仕組み
FunnelFlux Proのレポーティングは非常に柔軟で、ほとんど制限なくツリー状にグループ化できます。
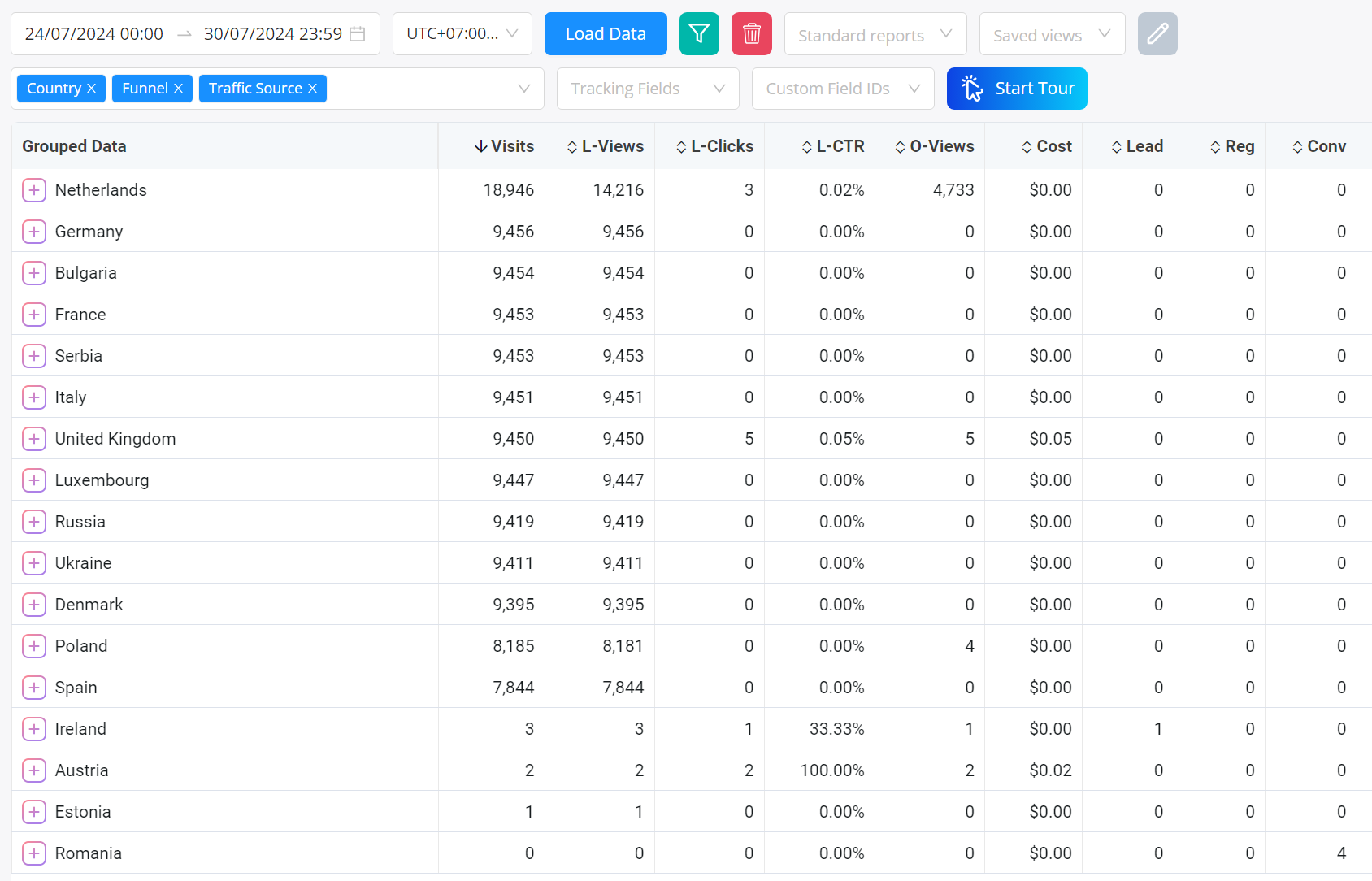
レポーティングページでは、日付/時間範囲を選択し、グループ化したい属性を順番に追加できます:
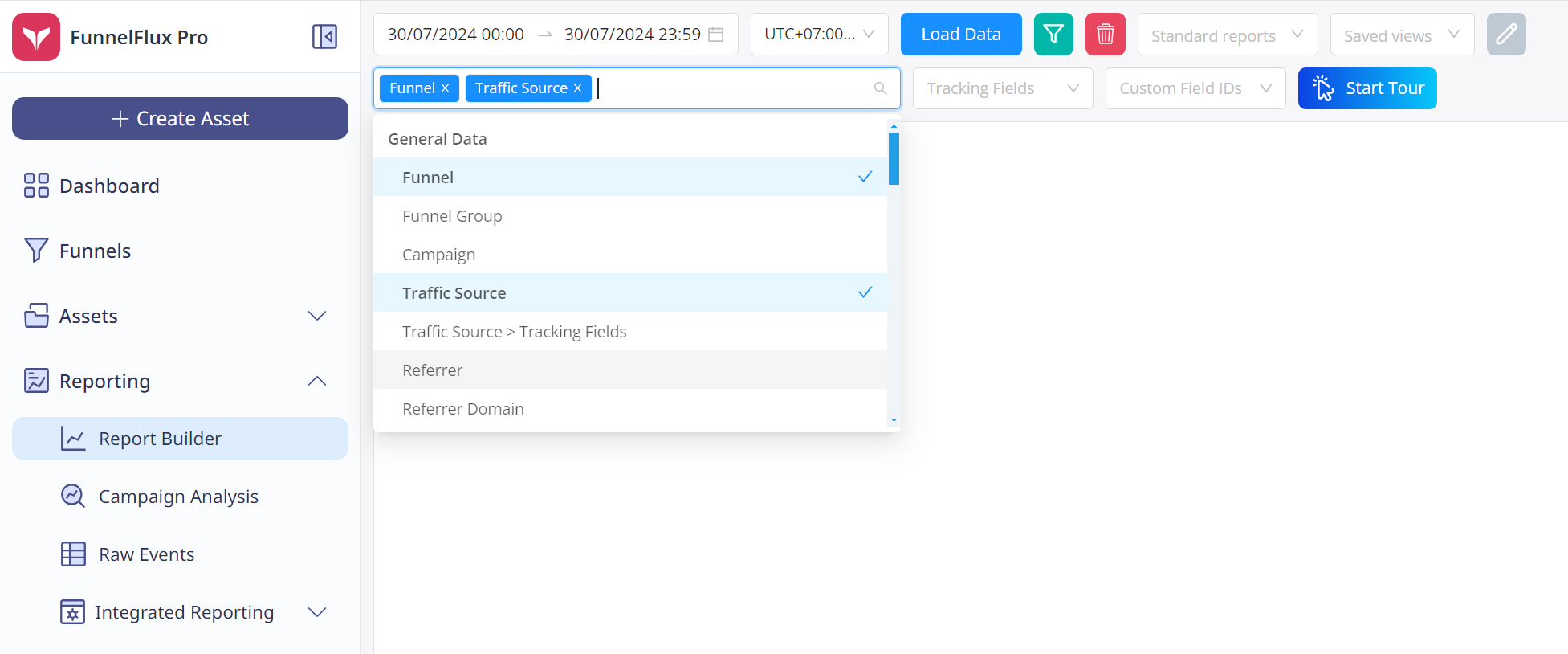
また、特定のプリセットに対する「標準レポート」の1つを読み込むこともできます:
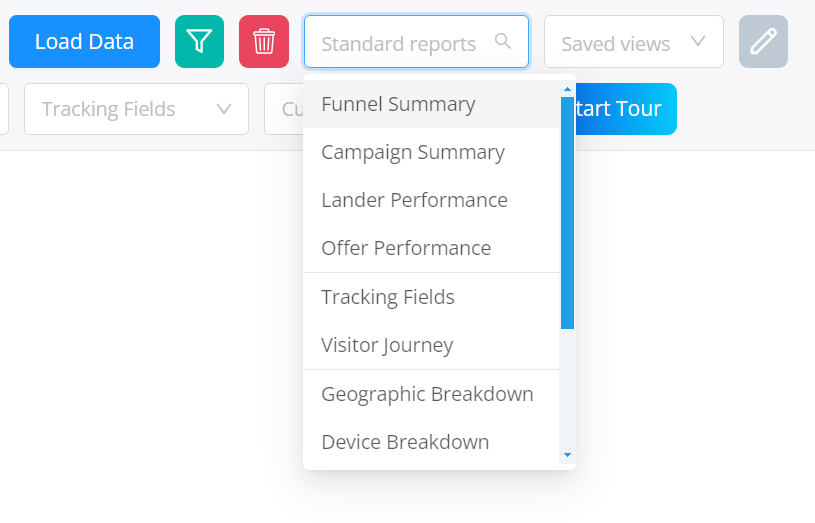
その後、適用をクリックしてレポートを読み込みます。
必要に応じてツリーを展開し、データをドリルダウンできます。
すべてのデータは展開時に遅延読み込みされます。これは、巨大な単一のレポートを生成しようとするのではなく、小さな部分で素早くデータを読み込むために行われています。
欠点は、完全なレポートをExcel/CSVに直接エクスポートできないことですが、後日この専用のエクスポート機能を提供する予定です。
列と表示するメトリクスの設定
表示する列を設定するには、フッターの列アイコンをクリックします(または「S」ホットキーをタップできます):
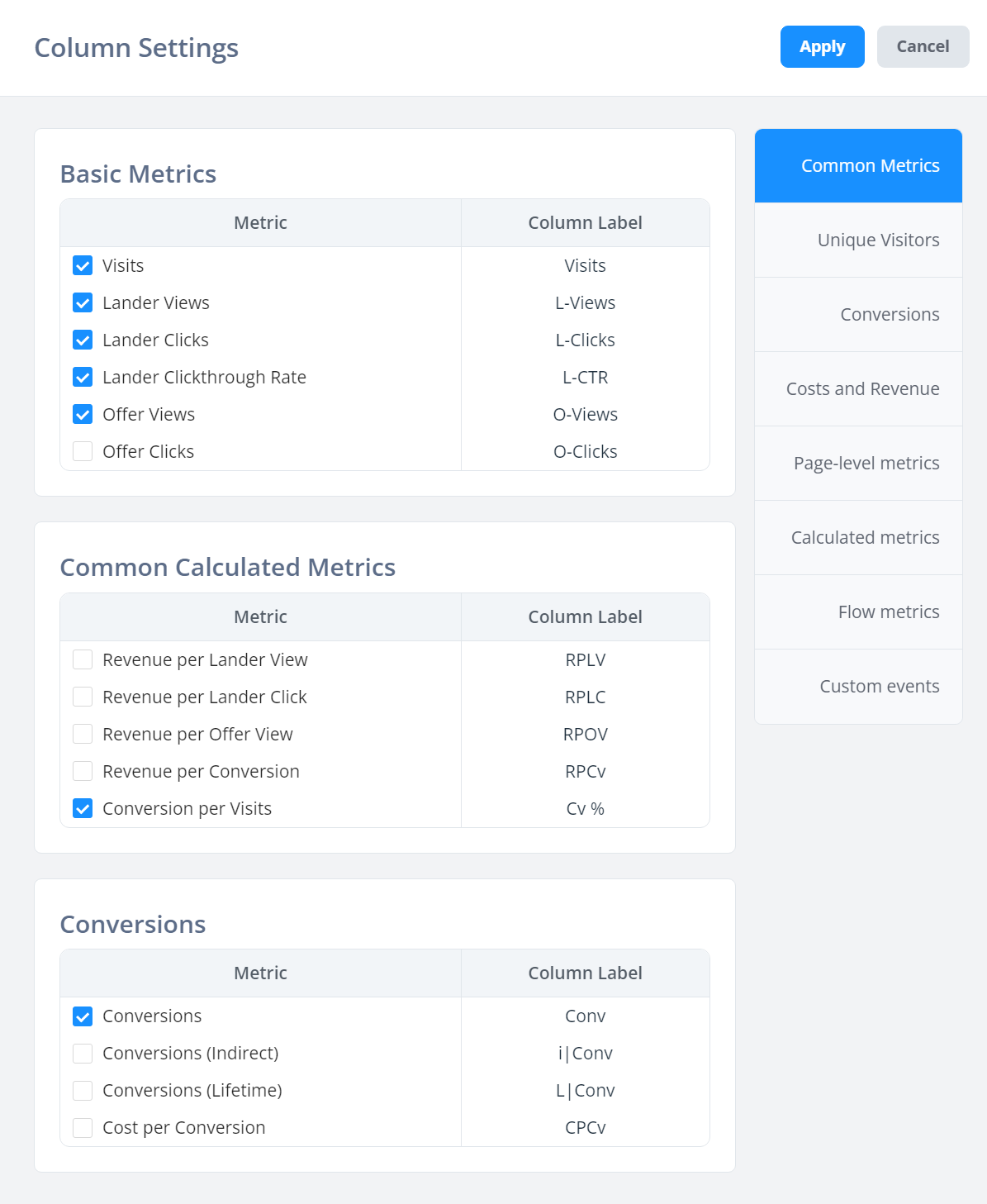
異なるタブを閲覧して、表示したい列を見つけることができます。
テーブルの列ヘッダーをドラッグして、異なる順序に移動できます。
各メトリクスの略語がその横に表示されていることに注意してください。例えば、Cost per Visitor | CPV -- テーブルでは、列名として「Cost per Visitor」ではなく「CPV」を表示します。これは列を狭く保つために行われており、そうしないとテーブルが不必要に広くなる可能性があります。
また、FunnelFluxでは、ランダーとオファーは2つの異なるタイプのページであり、それぞれ独自のビューとクリックメトリクスを持っていることに注意してください。
そのため、ランダーの行は常にオファービュー/クリック列でゼロを表示し、その逆も同様です。自社のオファーページを含むファネルがある場合(制御できないオファーが最終ページとなる典型的なアフィリエイトファネルとは対照的に)、オファービュー、クリック、CTR列を確認する必要があるかもしれません。
フィルタリングオプション
インラインフィルターまたはデータ制限オプションを使用して、2つの方法でフィルタリングできます。
インラインフィルターはフッターで、または「F」ホットキーでオンにできます:
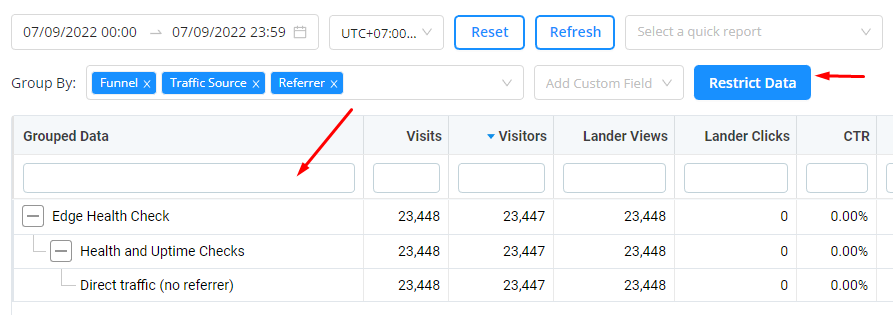
インラインフィルタリングは入力時に機能し、複数の列にデータを入力できます。
インラインフィルタリングは常に最も深い子要素に作用するため、上記の例で「dire..」と入力すると、親行ではなく「Direct traffic (no referrer)」行でフィルタリングされます。時には異なる行でフィルタリングしたい場合もありますが、現時点ではデフォルトオプションを1つ選ぶ必要があり、「最も深い行」オプションを選択しています。
数値列の場合、演算子を使用できます。例:>1000、<1000、1000-25000。
一方、データフィルタリングオプションを使用すると、特定の属性値を含めたり除外したりして、レポート全体のクエリをフィルタリングできます:
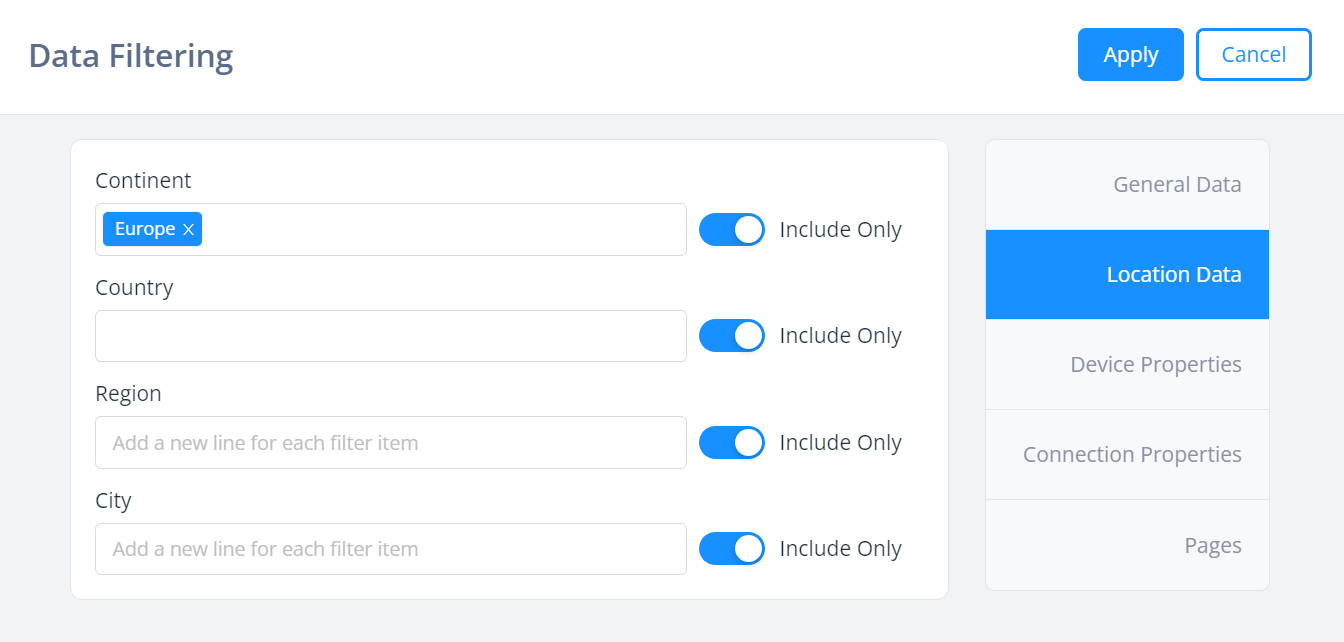
ここでは例えば、大陸がグループ化に含まれていなくても、ヨーロッパ大陸のみにフィルタリングすることができます:
適用をクリックすると、レポートが再読み込みされ、次のようになります:
アメリカ合衆国の行が消えていることに注目してください。これはレポート全体が大陸 = ヨーロッパのデータのみを表示しているためです。
ジャーニー属性の仕組み
「ジャーニー」レポートはFunnelFluxに固有のもので、複雑なファネルデータをテーブル形式で表示するために必要です。
まず、基本的なレポーティングについては、ファネル内の視覚的なヒートマップが見つかるかもしれません - そのためそこをチェックしてください。
FunnelFluxでは、ほとんどのトラッカーとは異なり、ページの規定された順序がありません。
多くのトラッカーでは、いくつかの特定のシーケンスのみがあります:
- トラフィック > オファー
- トラフィック > ランダー > オファー
- トラフィック > プリランダー > ランダー > オファー
FunnelFluxにはそのような要件はありません。ファネルは任意のシーケンスを行うことができ、ユーザーはどこからでも開始できます。特定の前後にランダーやオファーが存在する必要はありません。
例えば、ユーザーは次のように進む可能性があります:トラフィック > オファー > ランダー > オファー > ランダー > ランダー
このため、「ランダー + オファー」属性を提供することはできません。単に意味をなさないのです。
それは、街の人々に「単一のランチ食品アイテム + 単一の飲み物アイテムは何か」と尋ねるようなものです。ただし、食べ物を最初に食べ、その後飲み物を飲み、それぞれ1つずつ、そして正確にその順序で行う必要があります。
代わりに、我々はジャーニー属性を提供しており、ツリーを単純化するために特定のノードタイプを削除するいくつかのバリエーションがあります。
注意:ランダーとオファーの属性を一緒にグループ化しようとすると、自動的にジャーニーに統合されます。
これらは3つの属性 - フル、グループ、ページのみ - として利用可能です:
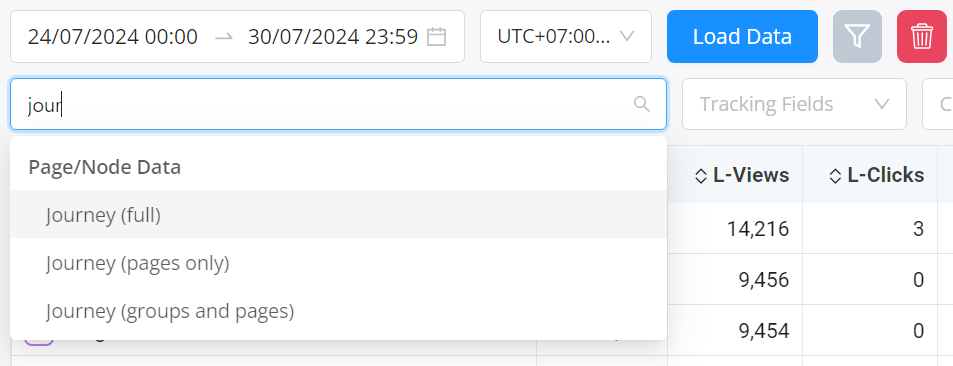
これらはすべて実際には完全なレポートを行っていますが、必要に応じてローテーターなどのノードを削除するための後処理フィルタリングを行っています。
このジャーニーレポーティングを使用して、ユーザーが通過するシーケンスと、各レベルでの訪問数、ビューあたりの収益などを理解してください。
常にファネルで最初にグループ化することを確認してください。そうしないとデータが意味をなさない可能性があります。
例:
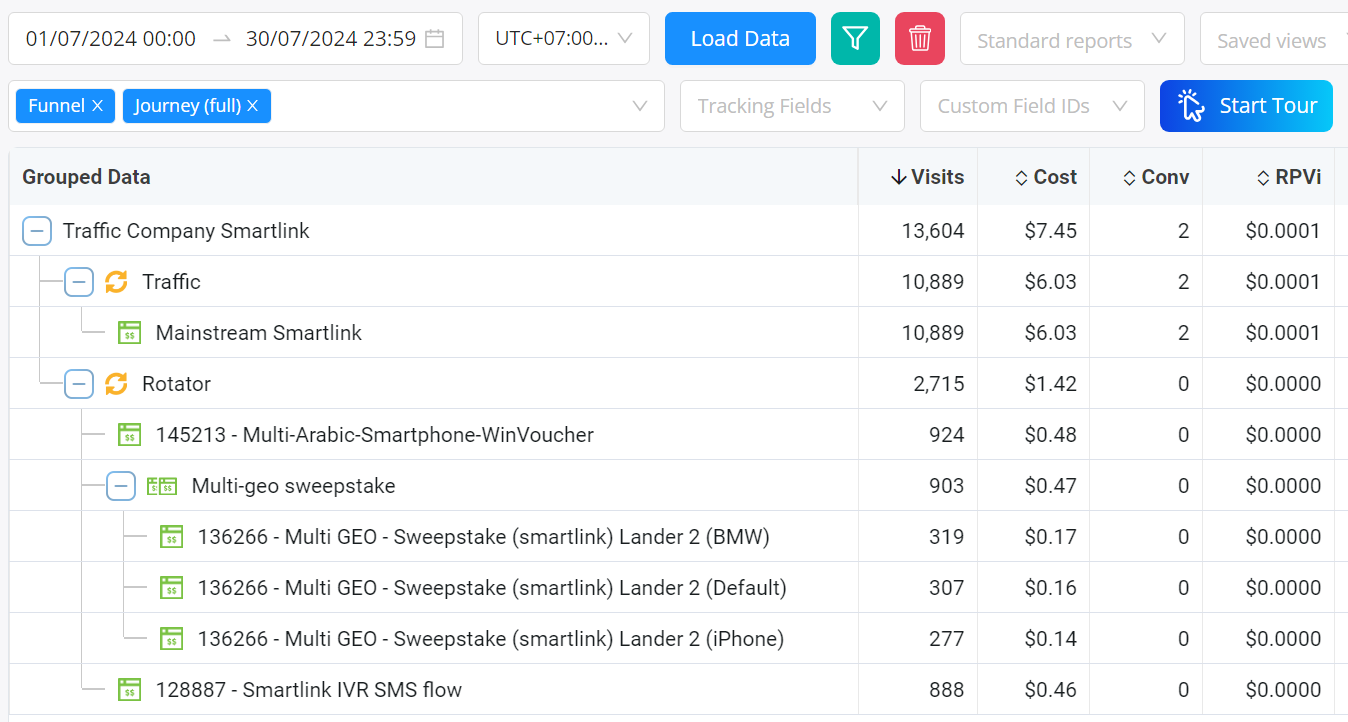
ここでは、トラフィックが2つの開始点 - トラフィックノードと他のローテーター - に向かったことがわかります。そこからメインストリームのスマートリンクオファーに進み、他のローテーターから3つのオファーグループに進みました。そのグループの1つには3つのオファーページがありました。
ジャーニーツリーでグループに1つのページしかない場合、それを1行に統合しますが、複数の場合は上記のMulti-geo sweepstakeのようなツリーになることに注意してください。
ジャーニーレポートでは、RPVi(訪問あたりの収益)がおそらくそのノード/レベルへの訪問あたりの収益を理解するための最も価値のあるメトリクスです。
それ以外では、オファービューあたりの収益(RPOV)がオファービューあたりの収益を示し、オファーの直接的なパフォーマンスを示します。
将来的には、フロー率(親に対してこのレベルに到達した人数の割合)や親に対する相対的なRPVなど、さらに深い分析のための他の列も追加する予定です。
URLデータ(キーワードなど)による内訳
よくある質問は、「キーワードデータを見るにはどうすればいいですか」というものです。
トラフィックソースから来るこのようなすべてのデータは、FunnelFluxのトラフィックソース設定で定義されているように、URLパラメータを介して渡されます。
これらをグループ化するには2つの方法があります。まず、特定のソースから特定のURLフィールドをここに追加するか、番号付きの列ID(これらのc1、c2 ID